
AI’s math problem: FrontierMath benchmark shows how far technology still has to go
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Artificial intelligence systems may be good at generating text, recognizing images, and even solving basic math problems—but when it comes to advanced mathematical reasoning, they are hitting a wall. A groundbreaking new benchmark, FrontierMath, is exposing just how far today’s AI is from mastering the complexities of higher mathematics.
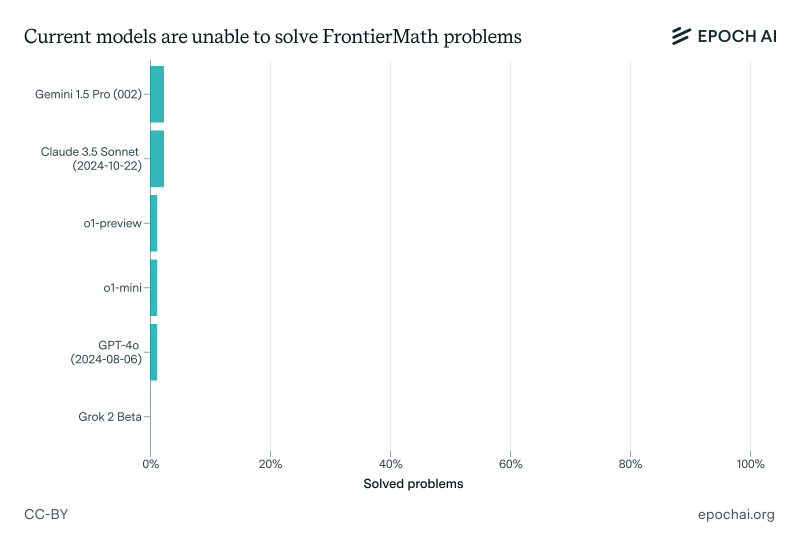
Developed by the research group Epoch AI, FrontierMath is a collection of hundreds of original, research-level math problems that require deep reasoning and creativity—qualities that AI still sorely lacks. Despite the growing power of large language models like GPT-4o and Gemini 1.5 Pro, these systems are solving fewer than 2% of the FrontierMath problems, even with extensive support.
“We collaborated with 60+ leading mathematicians to create hundreds of original, exceptionally challenging math problems,” Epoch AI announced in a post on X.com. “Current AI systems solve less than 2%.” The goal is to see how well machine learning models can engage in complex reasoning, and so far, the results have been underwhelming.
A Higher Bar for AI
FrontierMath was designed to be much tougher than the traditional math benchmarks that AI models have already conquered. On benchmarks like GSM-8K and MATH, leading AI systems now score over 90%, but those tests are starting to approach saturation. One major issue is data contamination—AI models are often trained on problems that closely resemble those in the test sets, making their performance less impressive than it might seem at first glance.
“Existing math benchmarks like GSM8K and MATH are approaching saturation, with AI models scoring over 90%—partly due to data contamination,” Epoch AI posted on X.com. “FrontierMath significantly raises the bar.”
In contrast, the FrontierMath problems are entirely new and unpublished, specifically crafted to prevent data leakage. These aren’t the kinds of problems that can be solved with basic memorization or pattern recognition. They often require hours or even days of work from human mathematicians, and they cover a wide range of topics—from computational number theory to abstract algebraic geometry.
Mathematical reasoning of this caliber demands more than just brute-force computation or simple algorithms. It requires what Fields Medalist Terence Tao calls “deep domain expertise” and creative insight. After reviewing the benchmark, Tao remarked, “These are extremely challenging. I think that in the near term, basically the only way to solve them is by a combination of a semi-expert like a graduate student in a related field, maybe paired with some combination of a modern AI and lots of other algebra packages.”

Why Is Math So Hard for AI?
Mathematics, especially at the research level, is a unique domain for testing AI. Unlike natural language or image recognition, math requires precise, logical thinking, often over many steps. Each step in a proof or solution builds on the one before it, meaning that a single error can render the entire solution incorrect.
“Mathematics offers a uniquely suitable sandbox for evaluating complex reasoning,” Epoch AI posted on X.com. “It requires creativity and extended chains of precise logic—often involving intricate proofs—that must be meticulously planned and executed, yet allows for objective verification of results.”
This makes math an ideal testbed for AI’s reasoning capabilities. It’s not enough for the system to generate an answer—it has to understand the structure of the problem and navigate through multiple layers of logic to arrive at the correct solution. And unlike other domains, where evaluation can be subjective or noisy, math provides a clean, verifiable standard: either the problem is solved or it isn’t.
But even with access to tools like Python, which allows AI models to write and run code to test hypotheses and verify intermediate results, the top models are still falling short. Epoch AI evaluated six leading AI systems, including GPT-4o, Gemini 1.5 Pro, and Claude 3.5 Sonnet, and found that none could solve more than 2% of the problems.

The Experts Weigh In
The difficulty of the FrontierMath problems has not gone unnoticed by the mathematical community. In fact, some of the world’s top mathematicians were involved in crafting and reviewing the benchmark. Fields Medalists Terence Tao, Timothy Gowers, and Richard Borcherds, along with International Mathematical Olympiad (IMO) coach Evan Chen, shared their thoughts on the challenge.
“All of the problems I looked at were not really in my area and all looked like things I had no idea how to solve,” Gowers said. “They appear to be at a different level of difficulty from IMO problems.”
The problems are designed not just to be hard but also to resist shortcuts. Each one is “guessproof,” meaning it’s nearly impossible to solve without doing the mathematical work. As the FrontierMath paper explains, the problems have large numerical answers or complex mathematical objects as solutions, with less than a 1% chance of guessing correctly without the proper reasoning.
This approach prevents AI models from using simple pattern matching or brute-force approaches to stumble upon the right answer. The problems are specifically designed to test genuine mathematical understanding, and that’s why they’re proving so difficult for current systems.
The Long Road Ahead
Despite the challenges, FrontierMath represents a critical step forward in evaluating AI’s reasoning capabilities. As the authors of the research paper note, “FrontierMath represents a significant step toward evaluating whether AI systems possess research-level mathematical reasoning capabilities.”
This is no small feat. If AI can eventually solve problems like those in FrontierMath, it could signal a major leap forward in machine intelligence—one that goes beyond mimicking human behavior and starts to approach something more akin to true understanding.
But for now, AI’s performance on the benchmark is a reminder of its limitations. While these systems excel in many areas, they still struggle with the kind of deep, multi-step reasoning that defines advanced mathematics.
Matthew Barnett, an AI researcher, captured the significance of FrontierMath in a series of tweets. “The first thing to understand about FrontierMath is that it’s genuinely extremely hard,” Barnett wrote. “Almost everyone on Earth would score approximately 0%, even if they’re given a full day to solve each problem.”
Barnett also speculated on what it might mean if AI eventually cracks the benchmark. “I claim that, once FrontierMath is completely solved, humans will be living alongside an entirely distinct set of intelligent beings,” he wrote. “We will be sharing this Earth with artificial minds that are, in an important sense, just as smart as we are.”
While that day may still be far off, FrontierMath provides a clear line in the sand—a way to measure progress toward true AI intelligence. As AI systems continue to improve, their performance on this benchmark will be closely watched by researchers, mathematicians, and technologists alike.

What’s Next for AI and Mathematics?
Epoch AI plans to expand FrontierMath over time, adding more problems and refining the benchmark to ensure it remains a relevant and challenging test for future AI systems. The researchers also plan to conduct regular evaluations, tracking how AI models perform as they evolve.
In the meantime, FrontierMath offers a fascinating glimpse into the limits of artificial intelligence. It shows that while AI has made incredible strides in recent years, there are still areas—like advanced math—where human expertise reigns supreme. But if and when AI does break through, it could represent a paradigm shift in our understanding of machine intelligence.
For now, though, the message is clear: when it comes to solving the hardest problems in math, AI still has a lot to learn.
Source link

