
Meta’s Transfusion model handles text and images in a single architecture
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Multi-modal models that can process both text and images are a growing area of research in artificial intelligence. However, training these models presents a unique challenge: language models deal with discrete values (words and tokens), while image generation models must handle continuous pixel values.
Current multi-modal models use techniques that reduce the quality of representing data. In a new research paper, scientists from Meta and the University of Southern California introduce Transfusion, a novel technique that enables a single model to seamlessly handle both discrete and continuous modalities.
The challenges of multi-modal models
Existing approaches to address the multi-modality challenge often involve different tradeoffs. Some techniques use separate architectures for language and image processing, often pre-training each component individually. This is the method used in models such as LLaVA. These models struggle to learn the complex interactions between different modalities, especially when processing documents where images and text are interleaved.
Other techniques quantize images into discrete values, effectively converting them into a sequence of tokens similar to text. This is the approach used by Meta’s Chameleon, which was introduced earlier this year. While this approach enables the use of language models for image processing, it results in the loss of information contained in the continuous pixel values.

Chunting Zhou, Senior Research Scientist at Meta AI and co-author of the paper, previously worked on the Chameleon paper.
“We noticed that the quantization method creates an information bottleneck for image representations, where discrete representations of images are highly compressed and lose information in the original images,” she told VentureBeat. “And in the meantime it’s very tricky to train a good discrete image tokenizer. Thus, we asked the question ‘Can we just use the more natural continuous representations of images when we train a multi-modal model together with discrete text?’”
Transfusion: A unified approach to multi-modal learning
“Diffusion models and next-token-prediction autoregressive models represent the best worlds for generating continuous and discrete data respectively,” Zhou said. “This inspired us to develop a new multi-modal method that combines the best of both worlds in a natural and simple way.”
Transfusion is a recipe for training a single model that can handle both discrete and continuous modalities without the need for quantization or separate modules. The core idea behind Transfusion is to train a single model with two objectives: language modeling for text and diffusion for images.
Transfusion combines these two objectives to train a transformer model that can process and generate both text and images. During training, the model is exposed to both text and image data, and the loss functions for language modeling and diffusion are applied simultaneously.
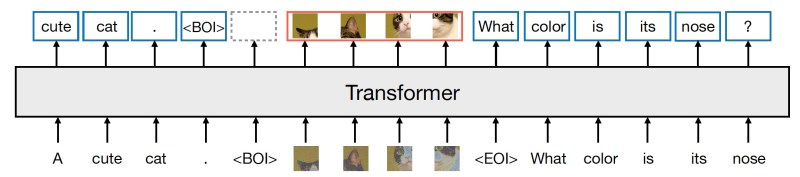
“We show it is possible to fully integrate both modalities, with no information loss, by training a single model to both predict discrete text tokens and diffuse continuous images,” the researchers write.
Transfusion uses a unified architecture and vocabulary to process mixed-modality inputs. The model includes lightweight modality-specific components that convert text tokens and image patches into the appropriate representations before they are processed by the transformer.
To improve the representation of image data, Transfusion uses variational autoencoders (VAE), neural networks that can learn to represent complex data, such as images, in a lower-dimensional continuous space. In Transfusion, a VAE is used to encode each 8×8 patch of an image into a list of continuous values.

“Our main innovation is demonstrating that we can use separate losses for different modalities – language modeling for text, diffusion for images – over shared data and parameters,” the researchers write.
Transfusion outperforms quantization-based approaches
The researchers trained a 7-billion model based on Transfusion and evaluated it on a variety of standard uni-modal and cross-modal benchmarks, including text-to-text, text-to-image, and image-to-text tasks. They compared its performance to an equally-sized model based on Chameleon, which is the current prominent open-science method for training native mixed-modal models.
In their experiments, Transfusion consistently outperformed the Chameleon across all modalities. In text-to-image generation, Transfusion achieved better results with less than a third of the computational cost of Chameleon. Similarly, in image-to-text generation, Transfusion matched Chameleon’s performance with only 21.8% of the computational resources.
Surprisingly, Transfusion also showed better performance on text-only benchmarks, even though both Transfusion and Chameleon use the same language modeling objective for text. This suggests that training on quantized image tokens can negatively impact text performance.
“As a replacement, Transfusion scales better than the commonly adopted multi-modal training approaches with discrete image tokens by a large margin across the board,” Zhou said.

The researchers ran separate experiments on image generation and compared Transfusion with other image generation models. Transfusion outperformed other popular models such as DALL-E 2 and Stable Diffusion XL while also being able to generate text.
“Transfusion opens up a lot of new opportunities for multi-modal learning and new interesting use cases,” Zhou said. “As Transfusion works just as LLM but on multi-modality data, this potentially unlocks new applications with better controllability on interactive sessions of user inputs, e.g. interactive editing of images and videos.”
Source link


