DeepMind makes big jump toward interpreting LLMs with sparse autoencoders
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Large language models (LLMs) have made remarkable progress in recent years. But understanding how they work remains a challenge and scientists at artificial intelligence labs are trying to peer into the black box.
One promising approach is the sparse autoencoder (SAE), a deep learning architecture that breaks down the complex activations of a neural network into smaller, understandable components that can be associated with human-readable concepts.
In a new paper, researchers at Google DeepMind introduce JumpReLU SAE, a new architecture that improves the performance and interpretability of SAEs for LLMs. JumpReLU makes it easier to identify and track individual features in LLM activations, which can be a step toward understanding how LLMs learn and reason.
The challenge of interpreting LLMs
The fundamental building block of a neural network is individual neurons, tiny mathematical functions that process and transform data. During training, neurons are tuned to become active when they encounter specific patterns in the data.
However, individual neurons don’t necessarily correspond to specific concepts. A single neuron might activate for thousands of different concepts, and a single concept might activate a broad range of neurons across the network. This makes it very difficult to understand what each neuron represents and how it contributes to the overall behavior of the model.
This problem is especially pronounced in LLMs, which have billions of parameters and are trained on massive datasets. As a result, the activation patterns of neurons in LLMs are extremely complex and difficult to interpret.
Sparse autoencoders
Autoencoders are neural networks that learn to encode one type of input into an intermediate representation, and then decode it back to its original form. Autoencoders come in different flavors and are used for different applications, including compression, image denoising, and style transfer.
Sparse autoencoders (SAE) use the concept of autoencoder with a slight modification. During the encoding phase, the SAE is forced to only activate a small number of the neurons in the intermediate representation.
This mechanism enables SAEs to compress a large number of activations into a small number of intermediate neurons. During training, the SAE receives activations from layers within the target LLM as input.
SAE tries to encode these dense activations through a layer of sparse features. Then it tries to decode the learned sparse features and reconstruct the original activations. The goal is to minimize the difference between the original activations and the reconstructed activations while using the smallest possible number of intermediate features.
The challenge of SAEs is to find the right balance between sparsity and reconstruction fidelity. If the SAE is too sparse, it won’t be able to capture all the important information in the activations. Conversely, if the SAE is not sparse enough, it will be just as difficult to interpret as the original activations.
JumpReLU SAE
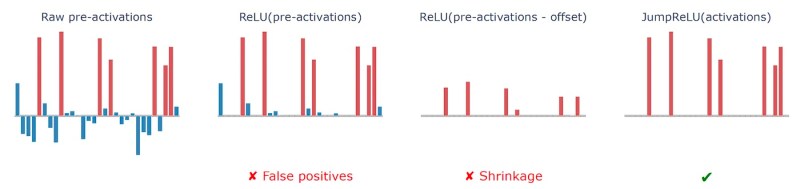
SAEs use an “activation function” to enforce sparsity in their intermediate layer. The original SAE architecture uses the rectified linear unit (ReLU) function, which zeroes out all features whose activation value is below a certain threshold (usually zero). The problem with ReLU is that it might harm sparsity by preserving irrelevant features that have very small values.
DeepMind’s JumpReLU SAE aims to address the limitations of previous SAE techniques by making a small change to the activation function. Instead of using a global threshold value, JumpReLU can determine separate threshold values for each neuron in the sparse feature vector.
This dynamic feature selection makes the training of the JumpReLU SAE a bit more complicated but enables it to find a better balance between sparsity and reconstruction fidelity.
The researchers evaluated JumpReLU SAE on DeepMind’s Gemma 2 9B LLM. They compared the performance of JumpReLU SAE against two other state-of-the-art SAE architectures, DeepMind’s own Gated SAE and OpenAI’s TopK SAE. They trained the SAEs on the residual stream, attention output, and dense layer outputs of different layers of the model.
The results show that across different sparsity levels, the construction fidelity of JumpReLU SAE is superior to Gated SAE and at least as good as TopK SAE. JumpReLU SAE was also very effective at minimizing “dead features” that are never activated. It also minimizes features that are too active and fail to provide a signal on specific concepts that the LLM has learned.
In their experiments, the researchers found that the features of JumpReLU SAE were as interpretable as other state-of-the-art architectures, which is crucial for making sense of the inner workings of LLMs.
Furthermore, JumpReLU SAE was very efficient to train, making it practical to apply to large language models.
Understanding and steering LLM behavior
SAEs can provide a more accurate and efficient way to decompose LLM activations and help researchers identify and understand the features that LLMs use to process and generate language. This can open the door to developing techniques to steer LLM behavior in desired directions and mitigate some of their shortcomings, such as bias and toxicity.
For example, a recent study by Anthropic found that SAEs trained on the activations of Claude Sonnet could find features that activate on text and images related to the Golden Gate Bridge and popular tourist attractions. This kind of visibility on concepts can enable scientists to develop techniques that prevent the model from generating harmful content such as creating malicious code even when users manage to circumvent prompt safeguards through jailbreaks.
SAEs can also give more granular control over the responses of the model. For example, by changing the sparse activations and decoding them back into the model, users might be able to control aspects of the output, such as making the responses more funny, easier to read, or more technical. Studying the activations of LLMs has turned into a vibrant field of research and there is a lot to be learned yet.
Source link

