
Microsoft’s GRIN-MoE AI model takes on coding and math, beating competitors in key benchmarks
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Microsoft has unveiled a groundbreaking artificial intelligence model, GRIN-MoE (Gradient-Informed Mixture-of-Experts), designed to enhance scalability and performance in complex tasks such as coding and mathematics. The model promises to reshape enterprise applications by selectively activating only a small subset of its parameters at a time, making it both efficient and powerful.
GRIN-MoE, detailed in the research paper “GRIN: GRadient-INformed MoE,” uses a novel approach to the Mixture-of-Experts (MoE) architecture. By routing tasks to specialized “experts” within the model, GRIN achieves sparse computation, allowing it to utilize fewer resources while delivering high-end performance. The model’s key innovation lies in using SparseMixer-v2 to estimate the gradient for expert routing, a method that significantly improves upon conventional practices.
“The model sidesteps one of the major challenges of MoE architectures: the difficulty of traditional gradient-based optimization due to the discrete nature of expert routing,” the researchers explain. GRIN MoE’s architecture, with 16×3.8 billion parameters, activates only 6.6 billion parameters during inference, offering a balance between computational efficiency and task performance.
GRIN-MoE outperforms competitors in AI Benchmarks
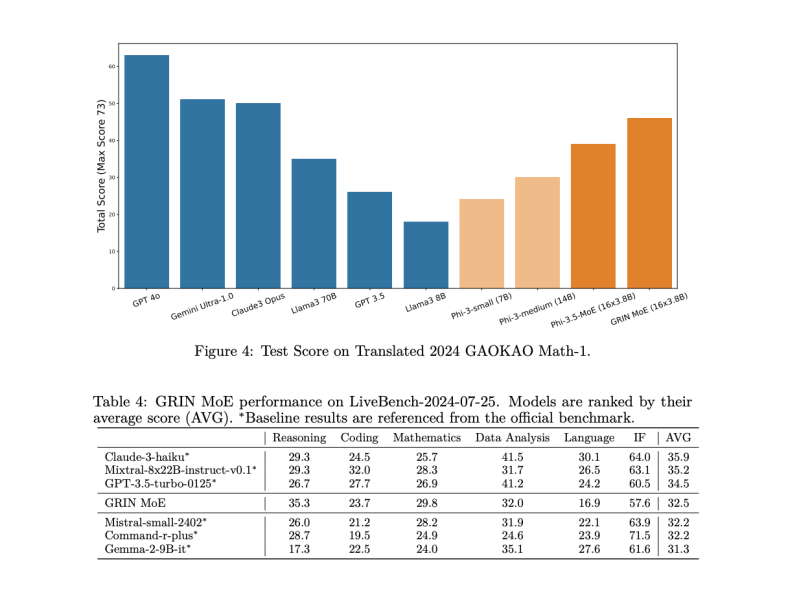
In benchmark tests, Microsoft’s GRIN MoE has shown remarkable performance, outclassing models of similar or larger sizes. It scored 79.4 on the MMLU (Massive Multitask Language Understanding) benchmark and 90.4 on GSM-8K, a test for math problem-solving capabilities. Notably, the model earned a score of 74.4 on HumanEval, a benchmark for coding tasks, surpassing popular models like GPT-3.5-turbo.
GRIN MoE outshines comparable models such as Mixtral (8x7B) and Phi-3.5-MoE (16×3.8B), which scored 70.5 and 78.9 on MMLU, respectively. “GRIN MoE outperforms a 7B dense model and matches the performance of a 14B dense model trained on the same data,” the paper notes.
This level of performance is particularly important for enterprises seeking to balance efficiency with power in AI applications. GRIN’s ability to scale without expert parallelism or token dropping—two common techniques used to manage large models—makes it a more accessible option for organizations that may not have the infrastructure to support bigger models like OpenAI’s GPT-4o or Meta’s LLaMA 3.1.

AI for enterprise: How GRIN-MoE boosts efficiency in coding and math
GRIN MoE’s versatility makes it well-suited for industries that require strong reasoning capabilities, such as financial services, healthcare, and manufacturing. Its architecture is designed to handle memory and compute limitations, addressing a key challenge for enterprises.
The model’s ability to “scale MoE training with neither expert parallelism nor token dropping” allows for more efficient resource usage in environments with constrained data center capacity. In addition, its performance on coding tasks is a highlight. Scoring 74.4 on the HumanEval coding benchmark, GRIN MoE demonstrates its potential to accelerate AI adoption for tasks like automated coding, code review, and debugging in enterprise workflows.
GRIN-MoE Faces Challenges in Multilingual and Conversational AI
Despite its impressive performance, GRIN MoE has limitations. The model is optimized primarily for English-language tasks, meaning its effectiveness may diminish when applied to other languages or dialects that are underrepresented in the training data. The research acknowledges, “GRIN MoE is trained primarily on English text,” which could pose challenges for organizations operating in multilingual environments.
Additionally, while GRIN MoE excels in reasoning-heavy tasks, it may not perform as well in conversational contexts or natural language processing tasks. The researchers concede, “We observe the model to yield a suboptimal performance on natural language tasks,” attributing this to the model’s training focus on reasoning and coding abilities.
GRIN-MoE’s potential to transform enterprise AI applications
Microsoft’s GRIN-MoE represents a significant step forward in AI technology, especially for enterprise applications. Its ability to scale efficiently while maintaining superior performance in coding and mathematical tasks positions it as a valuable tool for businesses looking to integrate AI without overwhelming their computational resources.
“This model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI-powered features,” the research team explains. As AI continues to play an increasingly critical role in business innovation, models like GRIN MoE are likely to be instrumental in shaping the future of enterprise AI applications.
As Microsoft pushes the boundaries of AI research, GRIN-MoE stands as a testament to the company’s commitment to delivering cutting-edge solutions that meet the evolving needs of technical decision-makers across industries.
Source link

